
Synthetic characters - Machine learning
Making Data
Synthetic data sets are imperative to training machine learning models, for it to get better we need to feed it a lot of data. Being able to iterate and create variations on data was key to this project, we needed to build out a pipeline that supported these workflows.
I designed and implemented the technical infrastructure of a synthetic data creation workflow that will produce millions of images of various 3D content. This allows researchers to use the datasets to quickly iterate parameters to train ML models without bias. This is key in creating software/hardware experiences for new immersive platforms.
Additionally, I was responsible for creating art directed corner cases of extremes or uncommon examples of characteristics to further improve training data. This work is still developing and the pipeline is still evolving to new production needs.
Creating a Baseline
Our pipeline uses some existing data sets with 56 IDs for both male and female models. I took these baselines and created a base shaders that I could start to modify and blend between all of the models. The ability to swap maps and shaders between these shared topologies is great for creating variation and blending to create new identities.
I used Dusan Kovic’s lookdev kit for setting up a look dev environment, the following videos are rendered in Arnold:



Flexible Pipeline
The pipeline for this project had to be very flexible and modular as it had to operate for workflows for artists/technical artists, engineers, and research scientists. Each of these users have varying expertise and technical understanding, so there has to be ways to bridge the gap between workstreams.
I proposed that we use USD through the pipeline as it would benefit more scriptable workflows as the format has the ability to create new stages (scenes) via python/c++ API or content creation tools. This would allow any user to generate changes or introduce variations without the need to know Maya or Houdini. Another plus is that we are able to use multiple render delegates via hydra to render scenes, this is helpful to the project running in many OS environments.
I was also able to implement more cloud based GPU virtual workstations to help in data generation and GPU based rendering. This was big in the past year due to COVID-19 changing how we all work and accelerating more flexible workflows from any location. A big part of our compute/render farm is based on the VMs for non PII sensitive data and having the ability to scale a ton of render workers has helped the small team deliver 100,000+ images for various data sets.
I SEE you
A lot of the problems I was assigned involved creating data around eyes and eye movement. There are ongoing developments in what direction we are going to take on shader complexity and flexibility of model vs displacement to introduce variance to data creation.
I had to create art directed models to hit edge cases to further improve the training data. This involved finding images of people that had physical features or characteristics that researchers knew they their training models needed and creating art assets from our baseline models. I sculpted features and details based on the reference photos and created a non-destructive system to add or remove these details using layers in Zbrush.
With these different edge cases built out and common topology we were also able to create new data that blended between all the models I created.














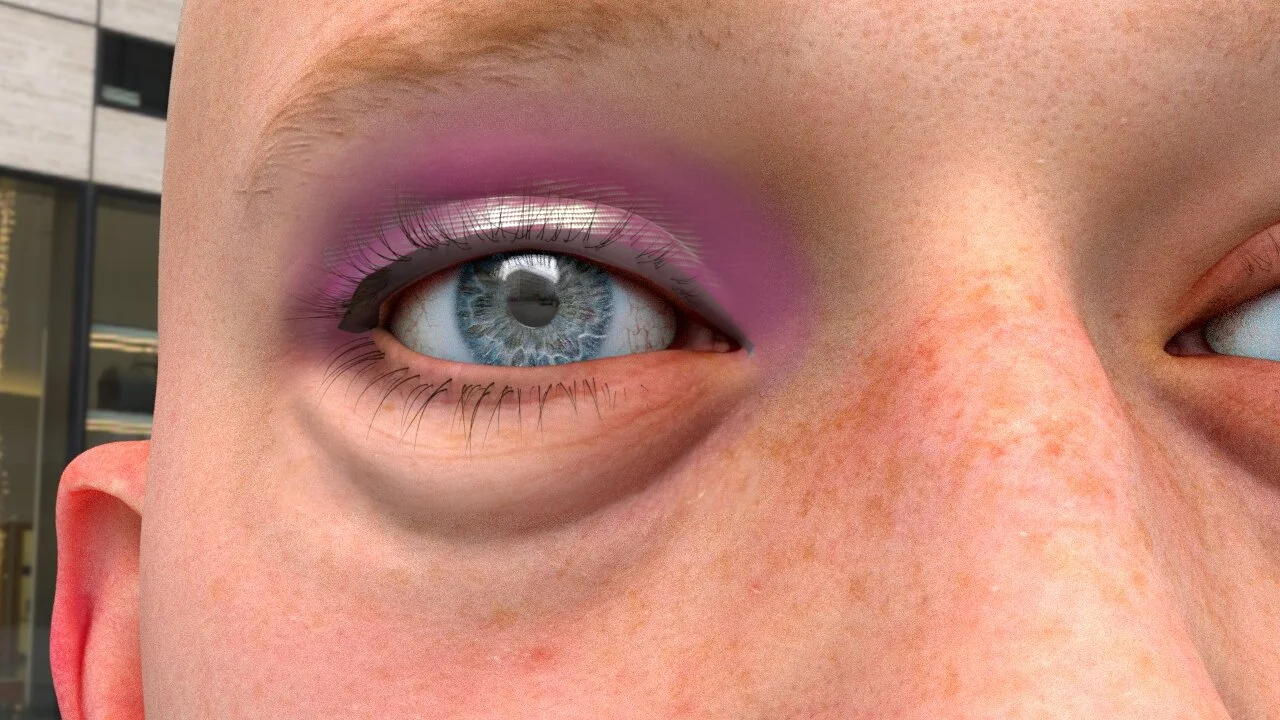













Makeup
For edge cases and real world variance, a makeup system was needed that could be applied to all of the synthetic characters we had in our data set, as well as a way for this to be projected on real world data to augment to create new training sets.
Below are the different layers to the shader I created, it is an additive material that is driven by procedurals or specified masks, with exposed parameters to change elements interactively. We used a second UV set for makeup specific tasks which I was able to incorporate into the transform space of the shader. The shader is flexible enough to replace each layer of makeup with any combination of BRDFs needed by researchers. This setup was flexible enough to be added to any of the models we had in our repo.
We are able to render this setup in Vray and Arnold currently and I am currently exploring porting to a materialx setup that will integrate into our USD based workflows for alternative render delegates.
Shader animation tests showing off environment rotations, rendered in Arnold.

Vray - No Makeup

Vray - Base

Vray - MId-eye

Vray - Glitter

Vray - Eyeliner